前言
牛客竞赛OJ高校创建赛功能目前仅开放给各校ACM负责人,需联系牛客工作人员开通权限(个人创建赛无封榜功能)。
本文内容适用于个人参赛模式(即每支队伍使用一个人的账号报名参赛),团队参赛大概率不适用。
报名时填写报名信息,昵称栏填写自己的牛客昵称,备注栏填写滚榜昵称(即队名),其他不做要求。
本文使用的Python脚本来自牛客网小羊肖恩大佬,由DeepSeek优化修改。如需添加/修改功能请自行研究,且务必遵守法律法规与平台规则!
脚本1会通过直接访问牛客网用户页面获取数据 (脚本发布已获得牛客工作人员许可),使用前也请获得许可。
一、工具准备
1. ICPC Tools-Resolver
- 本人使用的是2.6.1331版本
- 下载地址:https://tools.icpc.global
2. python环境配置
- Python 3.7或更高版本
- 需要安装的库:requests, beautifulsoup4, pandas, lxml…
- 用于运行py脚本
3. java环境配置
- JDK 1.8或更高版本
- 用于运行Resolver
4. 两个py脚本
py脚本1:getdata.py
- 功能:从牛客网爬取比赛提交记录,并将原始数据整理为结构化格式,同时将滚榜显示昵称替换为备注内容。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import datetime
import time
from typing import Dict, List, Set, Optional, Tuple
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
import os
class ContestDataProcessor:
"""比赛数据处理器 - 从牛客网爬取并处理比赛数据"""
def __init__(self, config: Dict = None):
"""
初始化处理器
Args:
config: 配置字典,包含文件路径、请求参数等
"""
self.config = config or {}
# 设置日志
self.setup_logging()
# 数据容器
self.register_df = None
self.submission_df = None
self.problems_df = None
self.processed_df = None
# 映射字典
self.nickname_to_remark = {}
self.is_group = {}
self.id_to_name = {}
self.problem_to_id = {}
# 请求会话
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
})
# 需要跳过的特殊用户
self.skip_users = {'YoungSean', '王清楚'}
def setup_logging(self):
"""设置日志配置"""
log_level = self.config.get('log_level', 'INFO')
logging.basicConfig(
level=getattr(logging, log_level),
format='%(asctime)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
self.logger = logging.getLogger(__name__)
def load_data_files(self):
"""加载所有数据文件"""
try:
# 加载注册信息
register_path = self.config.get('register_path', 'register.xls')
self.register_df = pd.read_excel(register_path)
self.logger.info(f"成功加载注册信息: {len(self.register_df)} 条记录")
# 加载提交记录
submission_path = self.config.get('submission_path', 'submission.xls')
self.submission_df = pd.read_excel(submission_path)
self.submission_df.sort_values(by='提交时间', inplace=True)
self.logger.info(f"成功加载提交记录: {len(self.submission_df)} 条记录")
# 加载题目信息
problems_path = self.config.get('problems_path', 'problems.xlsx')
self.problems_df = pd.read_excel(problems_path)
self.logger.info(f"成功加载题目信息: {len(self.problems_df)} 道题目")
except FileNotFoundError as e:
self.logger.error(f"找不到数据文件: {e}")
raise
except Exception as e:
self.logger.error(f"加载数据文件失败: {e}")
raise
def build_nickname_mapping(self):
"""构建昵称到备注的映射"""
skipped_count = 0
for idx in self.register_df.index:
info = self.register_df.loc[idx]
nickname = info['昵称']
# 跳过特殊用户
if nickname in self.skip_users:
skipped_count += 1
continue
# 获取备注(优先使用备注,否则使用昵称)
if pd.isna(info['备注']):
remark = nickname
else:
remark = info['备注']
self.nickname_to_remark[nickname] = remark
self.is_group[nickname] = info['团队'] == '是'
self.logger.info(f"构建昵称映射: {len(self.nickname_to_remark)} 个用户,跳过 {skipped_count} 个特殊用户")
def get_user_name(self, user_id: int) -> Optional[str]:
"""获取用户昵称(带重试机制)"""
max_retries = self.config.get('max_retries', 3)
retry_delay = self.config.get('retry_delay', 1)
for attempt in range(max_retries):
try:
site = f'https://ac.nowcoder.com/acm/contest/profile/{user_id}'
response = self.session.get(site, timeout=10)
response.raise_for_status()
bs = BeautifulSoup(response.text, features='html.parser')
title_tag = bs.find('title')
if title_tag:
name = str(title_tag)[7:-13] # 提取标题中的用户名
self.logger.debug(f"获取用户ID {user_id}: {name}")
return name
else:
self.logger.warning(f"用户ID {user_id}: 未找到标题标签")
except requests.exceptions.RequestException as e:
self.logger.warning(f"用户ID {user_id}: 第{attempt + 1}次请求失败 - {e}")
if attempt < max_retries - 1:
time.sleep(retry_delay * (attempt + 1)) # 递增延迟
else:
self.logger.error(f"用户ID {user_id}: 所有重试失败")
except Exception as e:
self.logger.error(f"用户ID {user_id}: 解析失败 - {e}")
break
return None
def build_id_to_name_mapping_single_thread(self):
"""单线程构建用户ID到昵称的映射"""
unique_user_ids = self.submission_df['用户id'].unique()
total_users = len(unique_user_ids)
self.logger.info(f"开始获取 {total_users} 个用户的昵称...")
for i, user_id in enumerate(unique_user_ids, 1):
if user_id not in self.id_to_name:
name = self.get_user_name(user_id)
if name:
self.id_to_name[user_id] = name
# 进度显示
if i % 10 == 0 or i == total_users:
self.logger.info(f"进度: {i}/{total_users} ({i / total_users * 100:.1f}%)")
self.logger.info(f"用户昵称获取完成: {len(self.id_to_name)}/{total_users} 个用户")
def build_id_to_name_mapping_multi_thread(self, max_workers: int = 5):
"""多线程构建用户ID到昵称的映射"""
unique_user_ids = self.submission_df['用户id'].unique()
total_users = len(unique_user_ids)
self.logger.info(f"开始多线程获取 {total_users} 个用户的昵称 (线程数: {max_workers})...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有任务
future_to_user_id = {
executor.submit(self.get_user_name, user_id): user_id
for user_id in unique_user_ids if user_id not in self.id_to_name
}
# 处理完成的任务
completed = 0
for future in as_completed(future_to_user_id):
user_id = future_to_user_id[future]
completed += 1
try:
name = future.result()
if name:
self.id_to_name[user_id] = name
except Exception as e:
self.logger.error(f"用户ID {user_id}: 获取昵称失败 - {e}")
# 进度显示
if completed % 10 == 0 or completed == total_users:
self.logger.info(f"进度: {completed}/{total_users} ({completed / total_users * 100:.1f}%)")
self.logger.info(f"用户昵称获取完成: {len(self.id_to_name)}/{total_users} 个用户")
def build_problem_mapping(self):
"""构建题目名称到编号的映射"""
for idx in self.problems_df.index:
info = self.problems_df.loc[idx]
problem_name = info['名称']
problem_id = info['题目编号']
self.problem_to_id[problem_name] = problem_id
self.logger.info(f"构建题目映射: {len(self.problem_to_id)} 道题目")
def process_submissions(self):
"""处理提交记录"""
processed_data = []
skipped_count = 0
for idx in self.submission_df.index:
info = self.submission_df.loc[idx]
user_id = info['用户id']
# 获取用户昵称
nickname = self.id_to_name.get(user_id)
if not nickname:
skipped_count += 1
continue
# 检查是否在注册表中
if nickname not in self.nickname_to_remark:
skipped_count += 1
continue
# 构建数据行
time_str = info['提交时间']
remark = self.nickname_to_remark[nickname]
team_suffix = '(团队)' if self.is_group.get(nickname, False) else '(个人)'
user_display = remark + team_suffix
problem_name = info['题目名称']
problem_id = self.problem_to_id.get(problem_name)
if not problem_id:
self.logger.warning(f"未知题目: {problem_name}")
skipped_count += 1
continue
status = info['提交状态']
processed_data.append({
'Time': time_str,
'User_ID': user_display,
'Problem_ID': problem_id,
'Passed': status
})
# 创建DataFrame
self.processed_df = pd.DataFrame(processed_data)
self.logger.info(f"处理提交记录完成: {len(self.processed_df)} 条有效记录,跳过 {skipped_count} 条")
def save_processed_data(self):
"""保存处理后的数据"""
output_path = self.config.get('output_path', 'submission_info.csv')
try:
# 确保输出目录存在
output_dir = os.path.dirname(output_path)
if output_dir: # 只有当输出路径包含目录时才创建
os.makedirs(output_dir, exist_ok=True)
# 保存CSV文件
self.processed_df.to_csv(output_path, index=False)
self.logger.info(f"数据已保存到 {output_path},共 {len(self.processed_df)} 条记录")
# 同时保存一份JSON格式,便于调试
json_path = output_path.replace('.csv', '.json')
if not json_path.endswith('.json'):
json_path += '.json'
self.processed_df.to_json(json_path, orient='records', force_ascii=False, indent=2)
self.logger.info(f"JSON格式数据已保存到 {json_path}")
# 保存映射信息用于调试
self.save_mapping_info()
except Exception as e:
self.logger.error(f"保存数据失败: {e}")
raise
def save_mapping_info(self):
"""保存映射信息用于调试"""
try:
# 保存昵称映射
mapping_data = {
'nickname_to_remark': self.nickname_to_remark,
'is_group': self.is_group,
'id_to_name': self.id_to_name,
'problem_to_id': self.problem_to_id
}
import json
mapping_path = self.config.get('output_path', 'submission_info.csv').replace('.csv', '_mapping.json')
if mapping_path.endswith('.csv'):
mapping_path = mapping_path.replace('.csv', '_mapping.json')
with open(mapping_path, 'w', encoding='utf-8') as f:
json.dump(mapping_data, f, ensure_ascii=False, indent=2, default=str)
self.logger.info(f"映射信息已保存到 {mapping_path}")
except Exception as e:
self.logger.warning(f"保存映射信息失败: {e}")
def display_summary(self):
"""显示处理摘要信息"""
print("\n" + "=" * 50)
print("数据处理完成摘要")
print("=" * 50)
print(f"\n1. 数据统计:")
print(f" 注册用户: {len(self.register_df)}")
print(f" 提交记录: {len(self.submission_df)}")
print(f" 有效记录: {len(self.processed_df)}")
print(f" 映射用户: {len(self.id_to_name)}")
print(f"\n2. 昵称到备注映射 (前10个):")
count = 0
for nickname, remark in list(self.nickname_to_remark.items())[:10]:
team_type = "团队" if self.is_group.get(nickname, False) else "个人"
print(f" {nickname} -> {remark} ({team_type})")
count += 1
if len(self.nickname_to_remark) > 10:
print(f" ... 还有 {len(self.nickname_to_remark) - 10} 个映射")
print(f"\n3. 题目映射 (前5个):")
count = 0
for problem_name, problem_id in list(self.problem_to_id.items())[:5]:
print(f" {problem_name} -> {problem_id}")
count += 1
if len(self.problem_to_id) > 5:
print(f" ... 还有 {len(self.problem_to_id) - 5} 道题目")
print(f"\n4. 输出文件:")
output_path = self.config.get('output_path', 'submission_info.csv')
print(f" CSV文件: {output_path}")
print(f" JSON文件: {output_path.replace('.csv', '.json')}")
mapping_path = output_path.replace('.csv', '_mapping.json')
print(f" 映射文件: {mapping_path}")
print("\n" + "=" * 50)
def run(self, use_multi_thread: bool = True):
"""运行数据处理流程"""
self.logger.info("开始处理比赛数据...")
try:
# 1. 加载数据文件
self.load_data_files()
# 2. 构建昵称映射
self.build_nickname_mapping()
# 3. 构建题目映射
self.build_problem_mapping()
# 4. 构建用户ID到昵称的映射
if use_multi_thread and self.config.get('use_multi_thread', True):
max_workers = self.config.get('max_workers', 5)
self.build_id_to_name_mapping_multi_thread(max_workers)
else:
self.build_id_to_name_mapping_single_thread()
# 5. 处理提交记录
self.process_submissions()
# 6. 保存处理后的数据
self.save_processed_data()
# 7. 显示摘要信息
self.display_summary()
self.logger.info("数据处理流程完成!")
except Exception as e:
self.logger.error(f"数据处理流程失败: {e}")
raise
def main():
"""主函数 - 配置和运行数据处理器"""
# 配置文件(可从此处修改所有参数)
config = {
# 文件路径
'register_path': 'register.xls',
'submission_path': 'submission.xls',
'problems_path': 'problems.xlsx',
'output_path': 'submission_info.csv', # 可以改为 'output/submission_info.csv' 如果有子目录
# 网络请求配置
'max_retries': 3, # 最大重试次数
'retry_delay': 1, # 重试延迟(秒)
'use_multi_thread': True, # 是否使用多线程
'max_workers': 5, # 最大线程数
# 日志配置
'log_level': 'INFO', # DEBUG, INFO, WARNING, ERROR
# 需要跳过的用户(可扩展)
'skip_users': ['YoungSean', '王清楚'],
}
# 创建处理器实例
processor = ContestDataProcessor(config)
# 运行处理器
try:
processor.run(use_multi_thread=config['use_multi_thread'])
except KeyboardInterrupt:
print("\n用户中断处理流程")
except Exception as e:
print(f"\n处理过程中发生错误: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()py脚本2:toxml.py
- 功能:将比赛提交记录转换为符合 ICPC 竞赛标准的 XML 格式文件,以便导入到滚榜程序中。
import pandas as pd
import datetime
from typing import Dict, Tuple, List, Any
class ContestXMLGenerator:
"""比赛XML文件生成器"""
def __init__(self, config: Dict[str, Any]):
"""
初始化生成器
Args:
config: 配置字典,包含比赛相关参数
"""
self.config = config
self.team_to_idx = {} # 队伍名称到ID的映射
self.problem_info = {} # 题目信息
self.submission_info = {} # 提交状态映射
@staticmethod
def str_to_timestamp(time_str: str) -> float:
"""将时间字符串转换为时间戳
Args:
time_str: 格式为 'YYYY-MM-DD HH:MM:SS' 的时间字符串
Returns:
对应的时间戳(浮点数)
"""
try:
date, timestamp = time_str.split()
y, m, d = (int(x) for x in date.split('-'))
hh, mm, ss = (int(x) for x in timestamp.split(':'))
return datetime.datetime(y, m, d, hh, mm, ss).timestamp()
except ValueError as e:
raise ValueError(f"时间格式错误: {time_str},应为 'YYYY-MM-DD HH:MM:SS'") from e
def load_data(self) -> pd.DataFrame:
"""加载提交记录数据"""
try:
# 不再使用 index_col=0,这样时间列不会被当作索引
df = pd.read_csv(self.config['data_path'])
print(f"成功加载数据,共 {len(df)} 条提交记录")
print("数据列名:", df.columns.tolist())
print("前3行数据示例:")
print(df.head(3))
return df
except FileNotFoundError:
raise FileNotFoundError(f"找不到数据文件: {self.config['data_path']}")
except Exception as e:
raise Exception(f"加载数据文件失败: {e}")
def initialize_problem_info(self):
"""初始化题目信息"""
# 基础题目配置
base_problems = {
'A': (1, 'Triangle', '#B80101'), # 红色
'B': (2, 'Zone', '#880CA1'), # 紫色
'C': (3, 'Mess', '#05C48F'), # 绿色
'D': (4, 'Coin', '#E8E8E8'), # 灰色
'E': (5, 'Digit', '#878787'), # 深灰色
'F': (6, 'Catepillar', '#27642A'), # 深绿色
'G': (7, 'Count', '#FFF500'), # 黄色
'H': (8, 'Outing', '#0625A1'), # 蓝色
'I': (9, 'Physical', '#01E5E6'), # 青色
'J': (10, 'Contest', '#E86700'), # 橙色
}
# 如果有自定义题目配置,使用自定义的
if 'problem_info' in self.config:
self.problem_info = self.config['problem_info']
else:
self.problem_info = base_problems
# 如果有额外题目,合并进来
if 'extra_problems' in self.config:
self.problem_info.update(self.config['extra_problems'])
def initialize_submission_info(self):
"""初始化提交状态映射"""
# 基础状态映射
base_mapping = {
'答案正确': ('Yes', 'true', 'false'),
'正在判题': ('Pending', 'false', 'false'),
'运行错误': ('No - Runtime Error', 'false', 'true'),
'答案错误': ('No - Wrong Answer', 'false', 'true'),
'执行出错': ('No - Runtime Error', 'false', 'true'),
'运行超时': ('No - Time Limit Exceeded', 'false', 'true'),
'内存超限': ('No - Memory Limit Exceeded', 'false', 'true'),
'输出超限': ('No - Output Limit Exceeded', 'false', 'true'),
'编译错误': ('Compile Error', 'false', 'false'),
'格式错误': ('No - Presentation Error', 'false', 'true'),
'内部错误': ('Internal Error', 'false', 'false'),
'浮点错误': ('No - Floating Point Error', 'false', 'true'),
'段错误': ('No - Segmentation Fault', 'false', 'true'),
'代码太长': ('Code Too Long', 'false', 'false'),
'返回非零': ('No - Return Non-Zero', 'false', 'true'),
}
# 如果有自定义状态映射,使用自定义的
if 'submission_mapping' in self.config:
self.submission_info = self.config['submission_mapping']
else:
self.submission_info = base_mapping
def generate_info_xml(self) -> str:
"""生成比赛信息XML片段"""
return f'''
<info>
<length>{self.config["total_time"]}:00:00</length>
<penalty>{self.config.get("penalty", 20)}</penalty>
<started>False</started>
<starttime>{self.config["start_time"]}</starttime>
<title>{self.config.get("title", "未命名比赛")}</title>
<short-title>{self.config.get("short_title", "比赛")}</short-title>
<scoreboard-freeze-length>{self.config["freeze_time"]}:00:00</scoreboard-freeze-length>
<contest-id>{self.config.get("contest_id", "unknown-contest")}</contest-id>
</info>'''
def generate_region_xml(self) -> str:
"""生成区域信息XML片段"""
region_id = self.config.get("region_id", 1)
region_name = self.config.get("region_name", "默认区域")
return f'''
<region>
<external-id>{region_id}</external-id>
<name>{region_name}</name>
</region>'''
def generate_submission_types_xml(self) -> str:
"""生成评判结果类型XML片段"""
submissions = []
for idx, submission_type in enumerate(self.submission_info, 1):
name, solved, penalty = self.submission_info[submission_type]
submissions.append(f'''
<judgement>
<id>{idx}</id>
<acronym>{submission_type}</acronym>
<name>{name}</name>
<solved>{solved}</solved>
<penalty>{penalty}</penalty>
</judgement>''')
return ''.join(submissions)
def generate_language_xml(self) -> str:
"""生成语言信息XML片段"""
return '''
<language>
<id>1</id>
<name>Unknown</name>
</language>'''
def generate_teams_xml(self, df: pd.DataFrame) -> str:
"""生成队伍信息XML片段"""
teams = []
unique_teams = sorted(set(df['User_ID']))
for idx, team in enumerate(unique_teams, 1):
self.team_to_idx[team] = idx
teams.append(f'''
<team>
<id>{idx}</id>
<external-id>{idx}</external-id>
<region>{self.config.get("region_name", "默认区域")}</region>
<name>{team}</name>
<university>{self.config.get("university_name", "未知学校")}</university>
</team>''')
print(f"共生成 {len(teams)} 支队伍信息")
return ''.join(teams)
def generate_problems_xml(self) -> str:
"""生成题目信息XML片段"""
problems = []
for problem_letter, (problem_id, problem_name, problem_rgb) in self.problem_info.items():
problems.append(f'''
<problem>
<id>{problem_id}</id>
<letter>{problem_letter}</letter>
<name>{problem_name}</name>
<rgb>{problem_rgb}</rgb>
<test_data_count>1</test_data_count>
</problem>''')
print(f"共生成 {len(problems)} 道题目信息")
return ''.join(problems)
def generate_runs_xml(self, df: pd.DataFrame) -> str:
"""生成提交记录XML片段"""
runs = []
valid_submissions = 0
skipped_submissions = 0
error_submissions = 0
contest_end_time = self.config["start_time"] + self.config["total_time"] * 3600
# 使用 iterrows() 遍历 DataFrame
for submission_id, (idx, row) in enumerate(df.iterrows(), 1):
try:
# 获取队伍ID
team_name = row['User_ID']
if team_name not in self.team_to_idx:
error_submissions += 1
print(f"警告:队伍 '{team_name}' 不在队伍列表中")
continue
team_id = self.team_to_idx[team_name]
# 获取题目ID
problem_letter = row['Problem_ID']
if problem_letter not in self.problem_info:
error_submissions += 1
print(f"警告:题目 '{problem_letter}' 不在题目列表中")
continue
problem_id = self.problem_info[problem_letter][0]
# 计算提交时间
time_str = row['Time']
submit_time = self.str_to_timestamp(time_str)
time_used = submit_time - self.config["start_time"]
timestamp = self.config["start_time"] + time_used
# 过滤比赛结束后的提交
if timestamp >= contest_end_time:
skipped_submissions += 1
continue
# 获取提交状态
status_key = row['Passed']
if status_key in self.submission_info:
_, solved, penalty = self.submission_info[status_key]
result = status_key
else:
_, solved, penalty = ('No', 'false', 'false')
result = status_key
# 生成XML片段
runs.append(f'''
<run>
<id>{submission_id}</id>
<judged>True</judged>
<language>Unknown</language>
<problem>{problem_id}</problem>
<status>done</status>
<team>{team_id}</team>
<time>{int(time_used)}</time>
<timestamp>{timestamp}</timestamp>
<solved>{solved}</solved>
<penalty>{penalty}</penalty>
<result>{result}</result>
</run>''')
valid_submissions += 1
except Exception as e:
error_submissions += 1
print(f"警告:处理记录 {idx} 时出错:{e}")
print(f"数据行: {row}")
continue
print(f"有效提交: {valid_submissions},跳过提交: {skipped_submissions},错误提交: {error_submissions}")
return ''.join(runs)
def generate_finalized_xml(self) -> str:
"""生成最终排名设置XML片段"""
contest_end_time = self.config["start_time"] + self.config["total_time"] * 3600
return f'''
<finalized>
<last_gold>{self.config.get("gold_count", 1)}</last_gold>
<last_silver>{self.config.get("silver_count", 2)}</last_silver>
<last_bronze>{self.config.get("bronze_count", 2)}</last_bronze>
<time>0</time>
<timestamp>{contest_end_time}</timestamp>
</finalized>'''
def generate_xml(self, df: pd.DataFrame) -> str:
"""生成完整的XML文档"""
xml_parts = [
'<contest>',
self.generate_info_xml(),
self.generate_region_xml(),
self.generate_submission_types_xml(),
self.generate_language_xml(),
self.generate_teams_xml(df),
self.generate_problems_xml(),
self.generate_runs_xml(df),
self.generate_finalized_xml(),
'\n</contest>\n'
]
return ''.join(xml_parts)
def save_xml(self, xml_content: str, output_path: str = None):
"""保存XML文件"""
if output_path is None:
output_path = self.config.get("output_path", "contest_xml/contest.xml")
import os
os.makedirs(os.path.dirname(output_path), exist_ok=True)
with open(output_path, 'w', encoding='utf-8') as fout:
fout.write(xml_content)
print(f"XML文件已保存到: {output_path}")
def run(self):
"""主运行流程"""
print("开始生成比赛XML文件...")
# 1. 初始化配置
self.initialize_problem_info()
self.initialize_submission_info()
# 2. 加载数据
df = self.load_data()
# 3. 生成XML
xml_content = self.generate_xml(df)
# 4. 保存文件
self.save_xml(xml_content)
print("比赛XML文件生成完成!")
def main():
"""主函数 - 配置和运行XML生成器"""
# 比赛配置(可从此处修改所有参数)
config = {
# 文件路径
'data_path': 'submission_info.csv',
'output_path': 'contest_xml/contest.xml',
# 比赛时间设置
'start_time_str': '2025-12-20 14:00:00', # 比赛开始时间
'total_time': 3, # 比赛总时长(小时)
'freeze_time': 1, # 封榜时间(小时)
'penalty': 20, # 错误提交罚时(分钟)
# 比赛信息
'title': '河南工程学院-第二届ACM程序设计竞赛',
'short_title': 'HAUE-ACM Round 2',
'contest_id': 'HAUE-ACM Round 2',
# 区域信息
'region_id': 2,
'region_name': 'HAUE',
'university_name': 'HAUE',
# 奖牌设置
'gold_count': 1,
'silver_count': 2,
'bronze_count': 2,
# 可选:自定义题目配置(如果与默认不同)
# 'problem_info': {
# 'A': (1, '自定义题目名', '#FF0000'),
# ...
# },
# 可选:额外题目(在默认10题基础上增加)
# 'extra_problems': {
# 'K': (11, 'Fiber', '#000000'),
# 'L': (12, 'Cruel', '#5F0CFF'),
# },
# 可选:自定义提交状态映射
# 'submission_mapping': {
# '自定义状态': ('ICPC状态', '是否解决', '是否罚时'),
# },
}
# 创建生成器实例
generator = ContestXMLGenerator(config)
# 处理时间转换
generator.config['start_time'] = generator.str_to_timestamp(config['start_time_str'])
try:
# 运行生成器
generator.run()
except Exception as e:
print(f"生成XML文件时出错: {e}")
import traceback
traceback.print_exc()
if __name__ == "__main__":
main()二、数据准备:三张关键表格
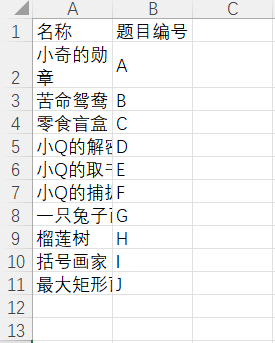
problems.xlsx,题目表。
- 来源:手动创建
- 格式如下:
register.xls,报名表。
来源:比赛后台导出
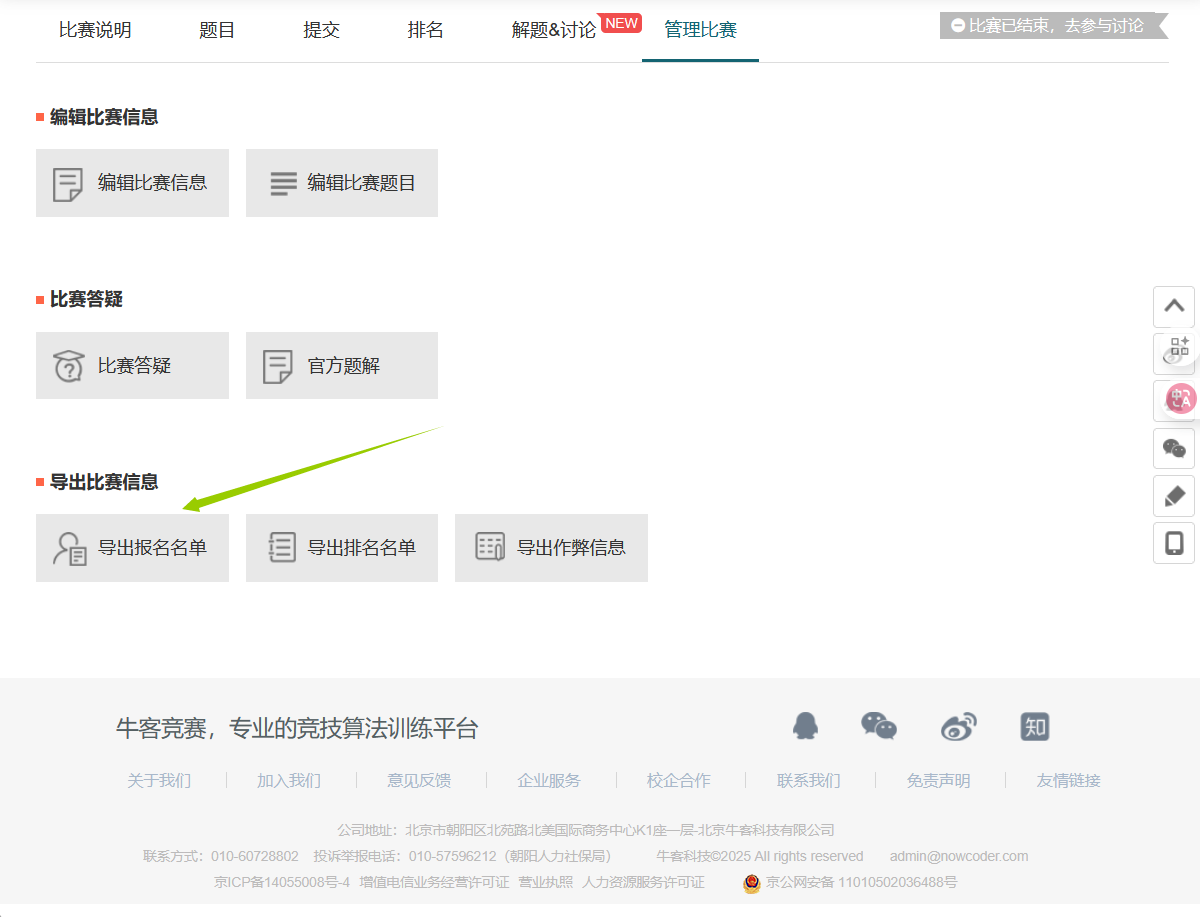
处理要求:
- 仅需保留”团队”、”昵称”、”备注”三列
- 昵称一定要与参赛者牛客昵称一致!
- 团队列:”是”→滚榜显示”(团队)”;”否”→显示”(个人)”
格式如下:

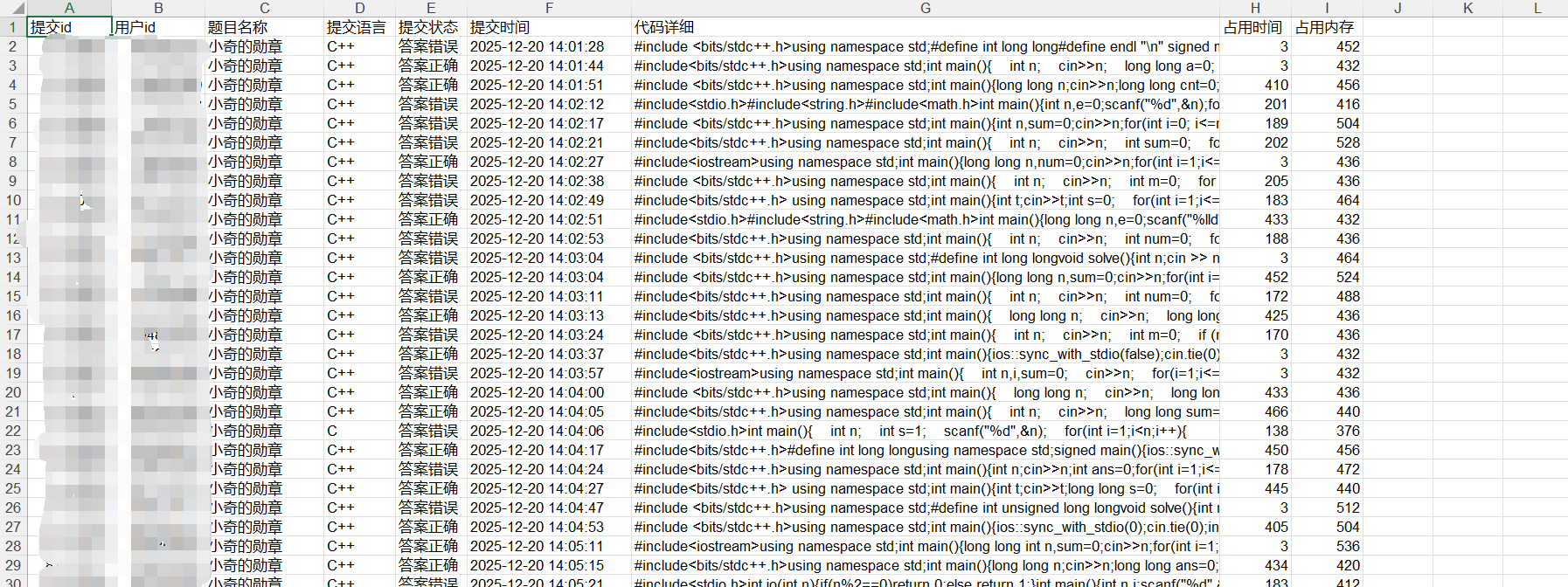
submission.xls,比赛提交数据表。
来源:比赛创建者登录状态下访问 https://ac.nowcoder.com/acm/admin/code-export?id=比赛ID
无需修改,格式如下:
三、运行py脚本
1. 文件准备
将三个表格文件和两个Python脚本放置在同一文件夹: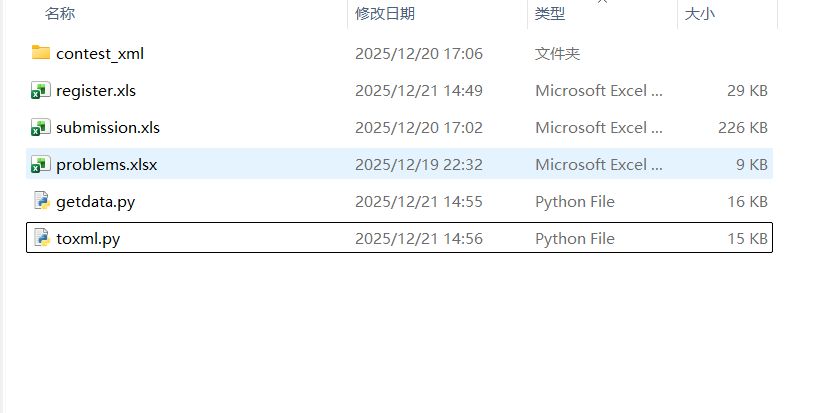
2. 运行getdata.py
运行完会生成一个csv文件与两个json文件(csv是主数据文件,json用于调试和数据追溯)。
3. 配置并运行toxml.py
修改toxml.py中的比赛配置: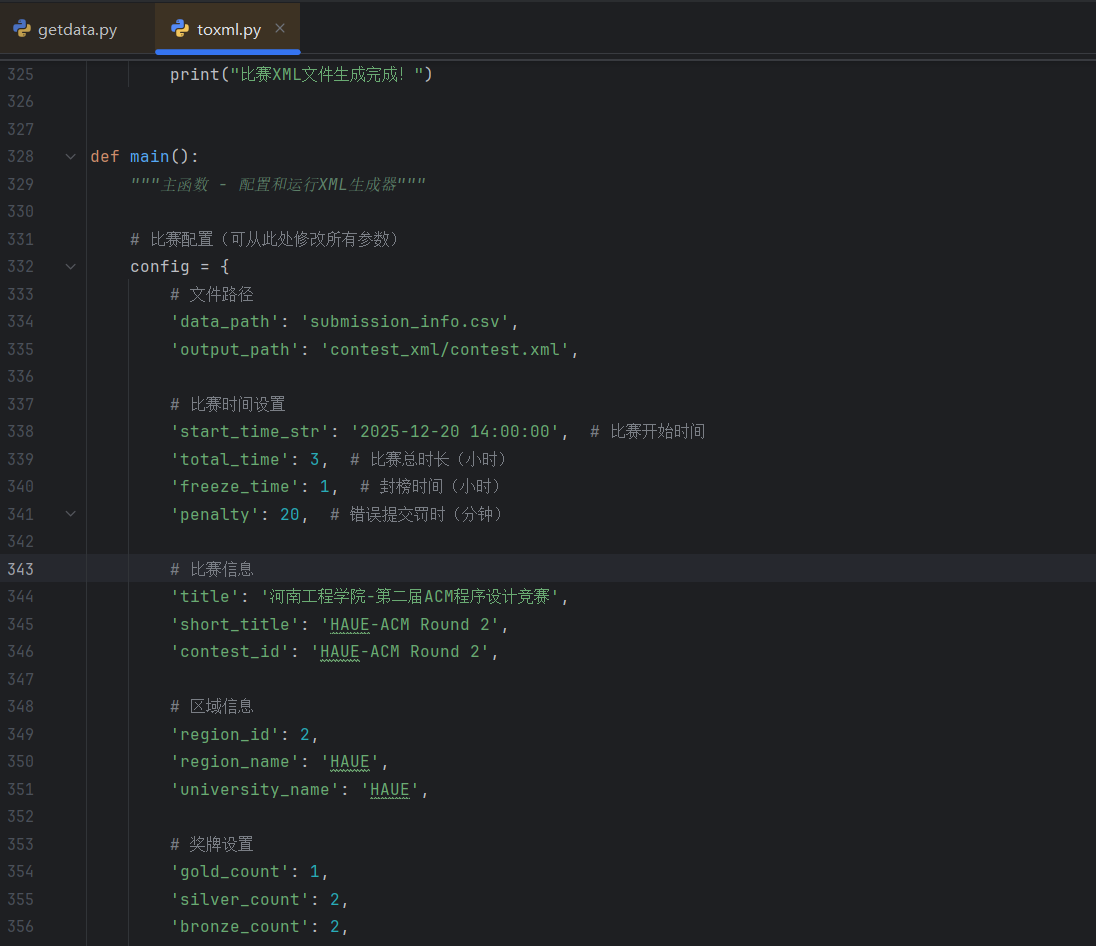
运行toxml.py,将csv文件转换为我们需要的xml格式,默认存储到contest_xml文件夹中。
四、运行resolver
resolver下载解压后文件夹默认包含以下文件:
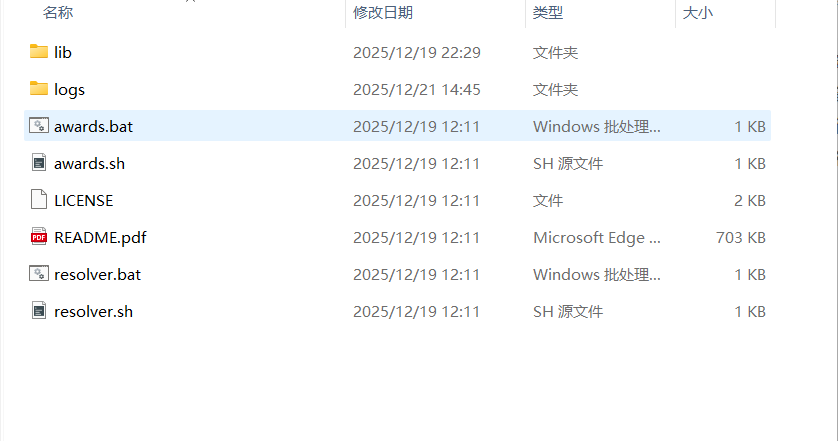
1. 替换中文字体(解决乱码问题)
- 进入lib文件夹,以压缩包形式打开presentation.jar;
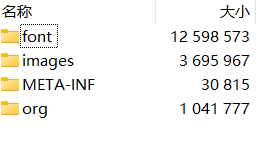
- 进入其中的font文件夹;
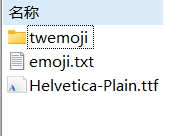
- 打开C:\Windows\Fonts(有可能不是这个地址?),找到一种中文字体(随便哪一种都可以);
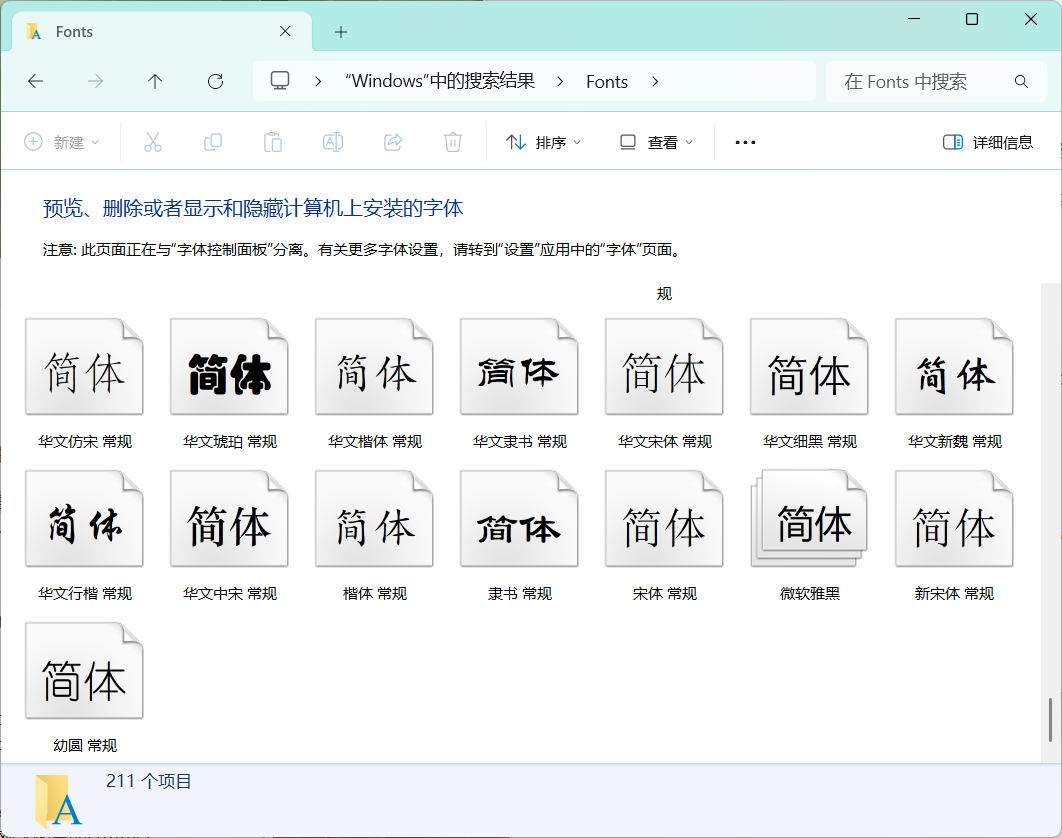
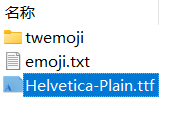
- 复制到压缩包的font文件夹中,将名字改为Helvetica-Plain.ttf,替换掉原来的Helvetica-Plain.ttf。
2. 生成ndjson文件
- 将第三步生成的contest.xml复制到Resolver文件夹。
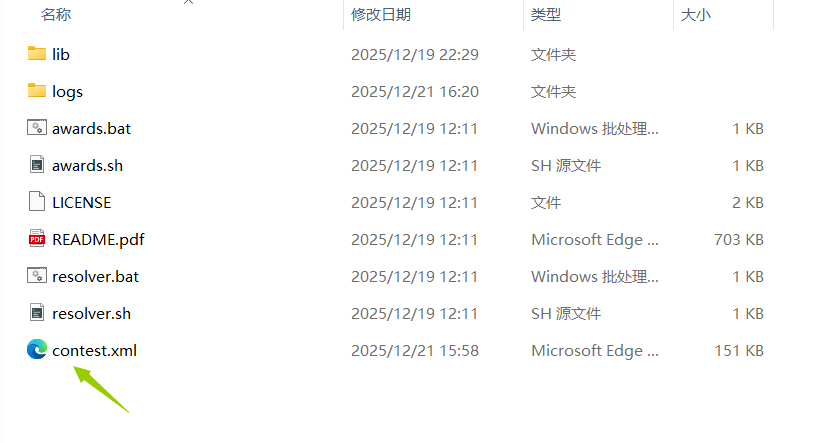
- cmd运行指令获取ndjson文件。(该指令是设置金银奖牌数量,但目的是获取ndjson文件,随意设置即可,后面还可以改)
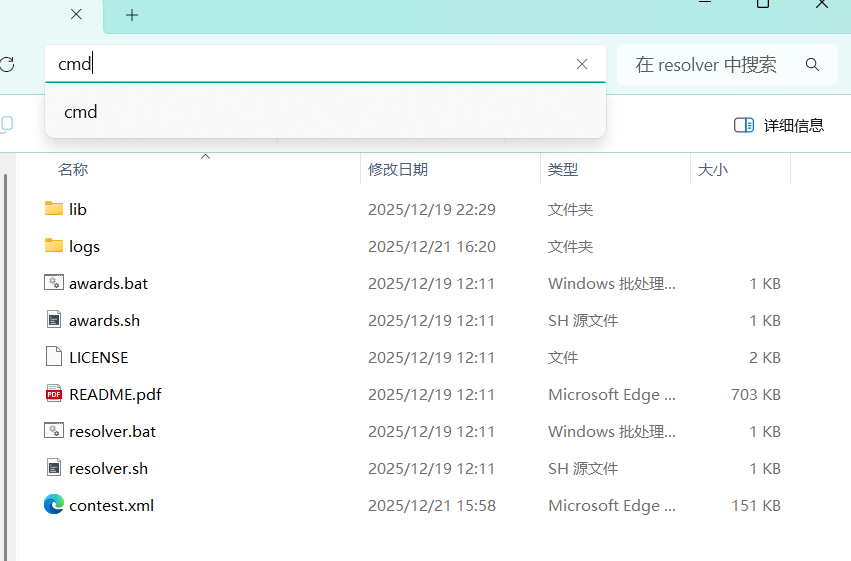
awards.bat contest.xml --medals 1 2 2 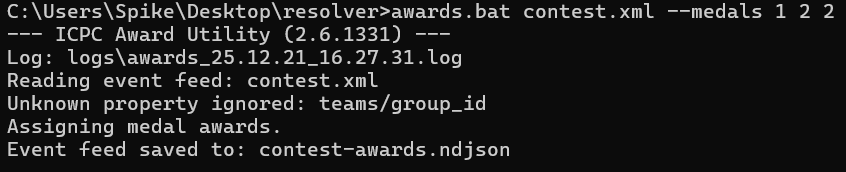
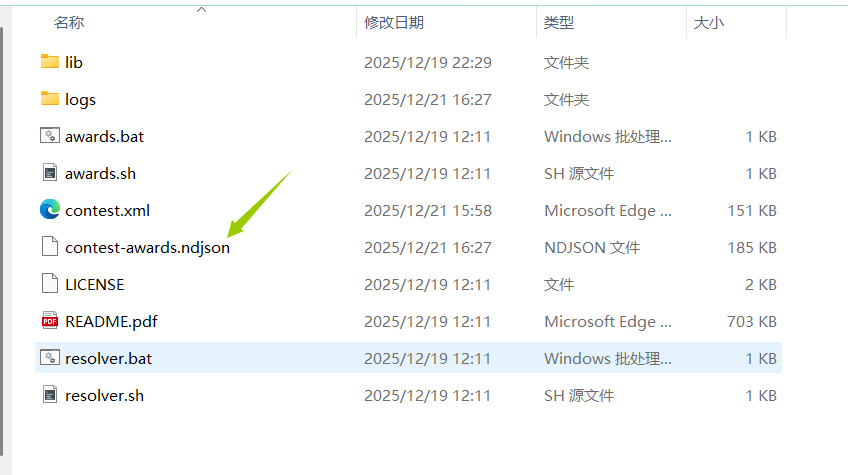
3. 配置滚榜参数
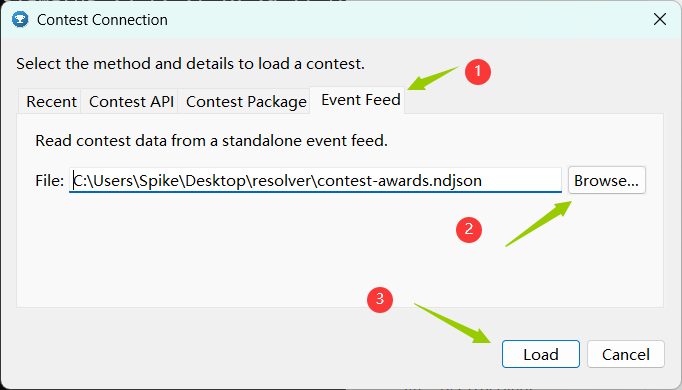
双击打开awards.bat,等待几秒后会出现图形界面。
在Event Feed中选择打开刚才生成的ndjson文件,Load。
 我在上方的报名表中团队列填的否,所以这里显示都是(个人)。
我在上方的报名表中团队列填的否,所以这里显示都是(个人)。
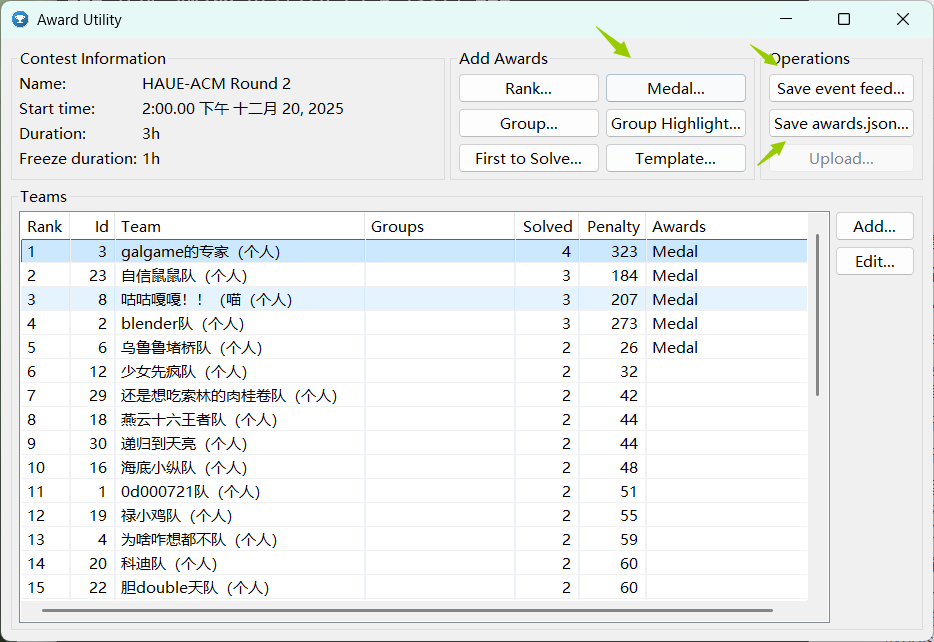
在上方的Medal…中可以重新设置金银铜奖牌数量。
其余功能请自行发掘。
完成设置后点击右上方的两个Save…,将文件保存到文件夹中。(我不知道awards.json是干嘛用的…)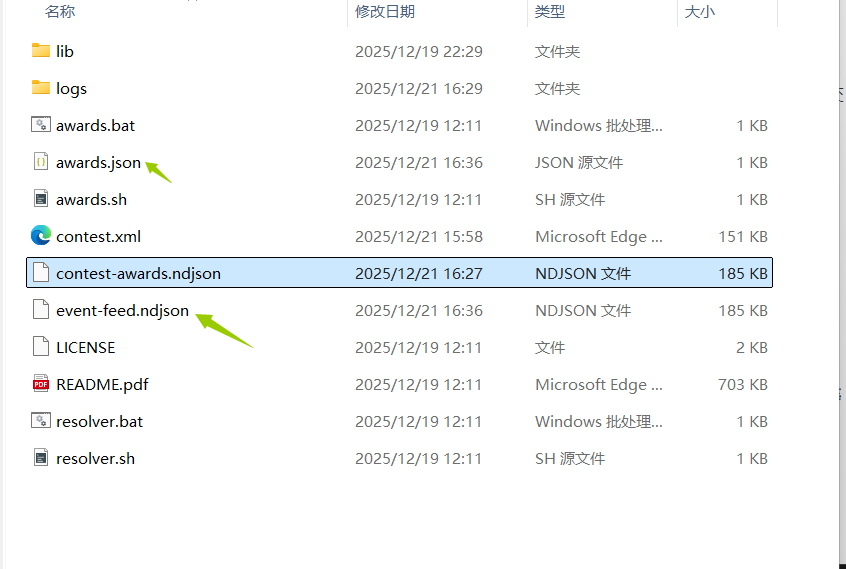
4. 启动滚榜!
- cmd运行指令启动滚榜(singleStep为手动模式)。
resolver.bat event-feed.ndjson --singleStep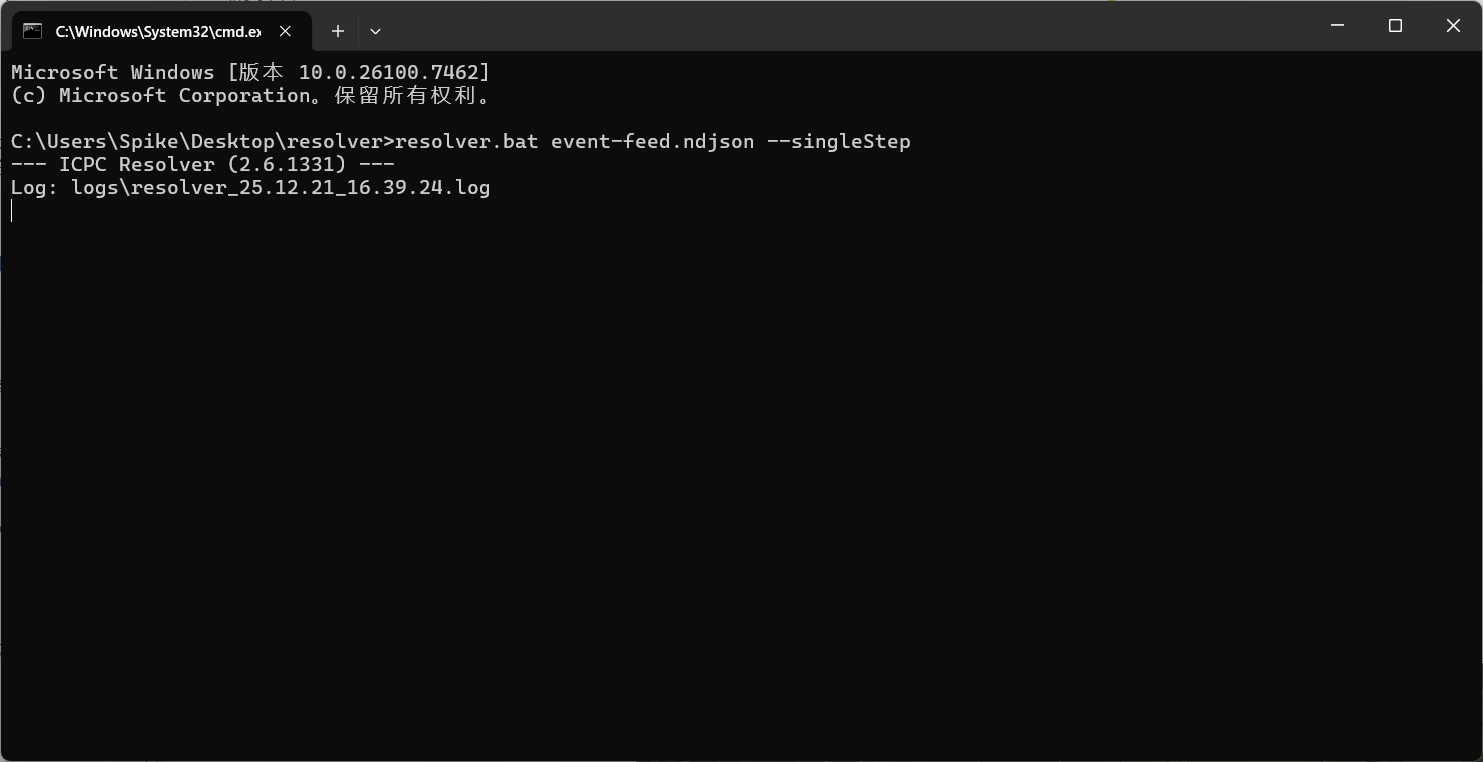
- 等待几秒后出现图形界面;
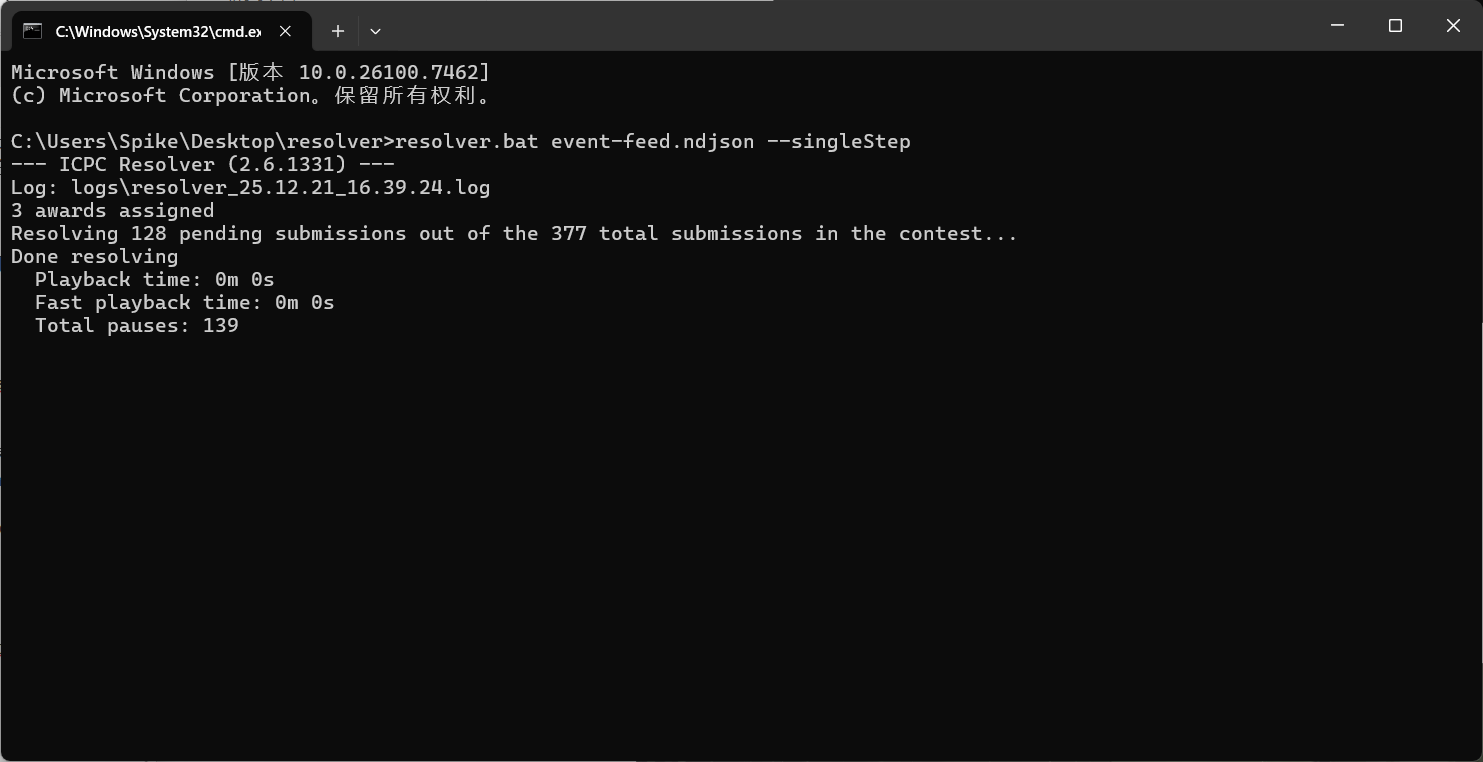

- 控制快捷键:
- 空格/数字2 下一步;
- R/数字1 上一步;
- ctrl+R 退出。
后记
坦白来说,我并没有专业的开发或运维背景。这次滚榜功能的实现,完全是参考了网上的零散教程,并借助AI花了两天时间反复尝试和调试才得以完成。
因此,本文内容可能存在疏漏或不准确之处。如果在实践过程中遇到问题,或发现文中有任何错误,非常欢迎大家批评指正,我也很乐意一起探讨解决。
最后,感谢你的阅读。希望这份摸索出来的经验,能帮你少走弯路,顺利实现比赛滚榜。


